iPhone emoji问题牵出的Unicode代理区的思考 |
您所在的位置:网站首页 › emoji 转unicode › iPhone emoji问题牵出的Unicode代理区的思考 |
iPhone emoji问题牵出的Unicode代理区的思考
|
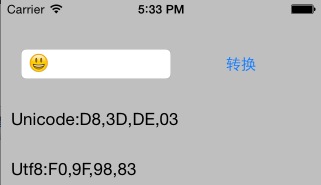
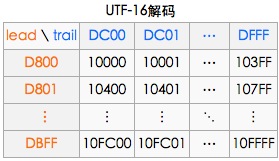
-------------------------------------------欢迎查看字符编码【专栏】------------------------------------------------------------------ 汉字编码之GBK编码【点击】 判断汉字正则表达式更严谨方法【点击】 记事本输入“联通”俩字,关闭再打开乱码 【点击】 iPhone emoji问题牵出的Unicode代理区的思考【点击】 Unicdoe【真正的完整码表】对照表【点击】 开源工程ZipArchive,压缩中文文件名乱码问题【点击】 base64加密,解密,encode,decode,编码详解+实现【点击】 网络传输文本,urlEncode和urldecode的iOS实现【点击】 字符编码的奥秘utf-8, Unicode【点击】 -------------------------------------------------------------------------------------------------------------------------------------------------- 前言iOS平台,系统输入法中带有emoji表情,该表情在很多其他平台上不能正常显示,尤其是之前的Android,Symbian系统;笔者决心探个究竟;笔者参考了几个知识点:(注意:该博文已经假设读者已经了解utf-8的知识了) 1. 笔者提供的“将字符串转化成unicode和utf-8”的工具。 2. 维基百科utf-16 3. 笔者博文,utf-8的介绍 4. 笔者博文,完整unicode码表(网页打开较慢) 问题描述在程序员和产品讨论emoji字符占用的字节数的时候,有人说2个、有人说4个、还有开发说iPhone的表情是iOS自定特定的。究竟emoji是几个字符呢?答案是4个,下面详细介绍一下: 在输入框输入一个emoji——微笑,然后通过UTF-8转化工具,看看它的编码是这样: 可以看到Unicode编码是 D83D-DE03。utf-8的编码是F09F-9883。常见字符Unicode很少四个字节的,这个不寻常的。通常utf-8是1到3个字节的,也就是说在Unicode编码空间的第0个平面上。可以简单推测:既然emoji的utf-8是4个字节,说明在1,2...16个平面中的某一个 。 这里有必要说明一下utf-8的编码规则(更多点击这里)如图所示: 我们再看看“微笑”的emoji符号的Unicode:D83D-DE03,已经超过了表格中最大的0X10FFFF了,怎么回事???下面我们根据utf-8的值:F09F-9883.来反推Unicode对应的数值吧,看看究竟是为什么: 得出的结果是0x1-F603,我把这个值叫做UTF-16.这个结果跟Unicode:D83D-DE03的值相差很大,所以,中间肯定经过了一些转换步骤,这个转换就是utf-16的代理!!! UFT-16UTF是"Unicode/UCS Transformation Format"的首字母缩写,即把Unicode字符转换为某种格式之意。上面第二张图片展示的是utf-8和unicode的对应表,这只是一个简单的对应,却非常好用。 在正常情况下一个Unicode两个字节,在转化uft-8的时候,根据协议,两个两个字节,对应一个uft-8这样完成转化或者称为映射! 其实在第0个平面中,专门有一个代理区域,不表示任何字符,只用于指向第1到第16个平面中的字符,这段区域是:D800——DFFF.。其中0xD800——0xDBFF是前导代理(lead surrogates).0xDC00——0xDFFF是后尾代理(trail surrogates). 一个代理对儿(前导,后尾),就表示一个utf-16的字符。就那emoji的微笑来说,前导是代理:D83D;后尾代理是:DE03。根据下图可以得出utf-16的值是:0x1-F603。这就照应上了。 具体的公式是:0x10000 + (前导-0xD800) * 0x400 + (后导-0xDC00) = utf-16编码。 就我们说的例子emoji而言,代入前导和后导,结果是:0x10000+(0xD83D - 0xD800)*0x400 + (0xDE03-0xDC00) = 0x1F603 作为程序员的我们,笔者做一个形象的比喻:这对儿(前导代理,后尾代理)就像一个指针,指向了第1——16平面上的每一个码位。经过计算,不难得出:16个平面 * 每个平面码位65536 = 1,048,576个,前导X后尾代理,可以表示的码位也是1,048,576个(哈!真是一个完美的解决方案)如上图所示。 这样做的好处是:程序根据Unicode的第一个字节来判断:(伪代码) if(Unicode第一个字节 >=0xD8 && Unicode |


【本文地址】